Archive
Using GeoSeer to find geospatial data
GeoSeer (https://www.geoseer.net) is a search engine for spatial data covering (at the time of this writing) over 1.2 million distinct spatial datasets from over 180,000 public OGC services (Web Map Services (WMS), Web Feature Services (WFS), Web Coverage Services (WCS), and Web Map Tile Services (WMTS)).
There are a huge number of OGC services online but they’re largely invisible. GeoSeer is designed to solve this “discoverability problem”, similar to how regular search engines like Google, Bing, and DuckDuckGo find web pages, but GeoSeer is focused on OGC services. In fact, I was originally drawn to GeoSeer because of their statement, “We created GeoSeer to solve a problem: it’s an absolute pain to find spatial data.” Indeed, this was one driving force for our book and this blog! Another thing that attracted me was its simple interface (see below), which reminded me, after years of using 37.com, Webcrawler, AltaVista, and other web search tools over the 1990s, the first time I saw the simple but powerful Google search interface.
The GeoSeer bot scrapes over 350 Open Data portals looking for OGC services to add to the index, including the ArcGIS Hub Open Data Portal [1], the Global Earth Observation System of Systems (GEOSS) Portal [2], and many others. By scraping all of these portals and combining all of the discovered services into a single search engine, GeoSeer makes it easy to find open and public spatial data. One can search by bounding box, lat-long, and service type, as explained here.
For end users, the benefits are a much easier data discovery process, while for the data providers it improves uptake of services and data that would otherwise be invisible and unused. GeoSeer also includes an API to allow organisations to use the search functionality in their own WebGIS or application, allowing non-expert users to easily find and use these services. I also liked working with the map-based interface to find data (see below).
How do you obtain data once you have found it? GeoSeer is designed to demonstrate how the API can be integrated into a webGIS. Rather than trying to be a full webGIS, it was created to demonstrate how smooth the entire search-add process can be for end-users with the API. It is a search engine to data, but unlike some of the other resources we have reviewed here, itself does not contain data. Data can be downloaded via WFS or WCS. WFS are raw vector/Feature data, while WCS are raw raster/Coverage data. If data is WMS/WMTS, then what the user sees is a pre-rendered map only. Some datasets are available via multiple services, which is why GeoSeer says “distinct” in its “1.2 million distinct spatial layers” statements. A statistics page shows how many of each data type GeoSeer has in its index: https://www.geoseer.net/stats/
To properly interact with the resulting data, the user will need to load the data into a proper (web) GIS. The simplest way to do that is to use the regular search, which for me was to search for trails along the Front Range of Colorado, which netted me this link to the Denver Regional Council of Governments page: https://www.geoseer.net/rl.php?ql=7aa26a5ae9fe3e4c. Not all services findable on GeoSeer are available via WFS or WCS. For example, if my trails data service was only a WMS, I could not download the data. At the top of my search results, I had two URLs: “WMS GetCapabilities URL” and “WFS GetCapabilities URL”. The WMS version gets me to the pre-rendered map, which is what I saw displayed on the GeoSeer map screen; and the WFS allowed me to download the raw vector data.
I invite you to give GeoSeer a try!
[1] – https://spatialreserves.wordpress.com/2018/12/10/finding-data-on-arcgis-hub-open-data-portal/
[2] – https://spatialreserves.wordpress.com/?s=geoss

Search screen for GeoSeer.
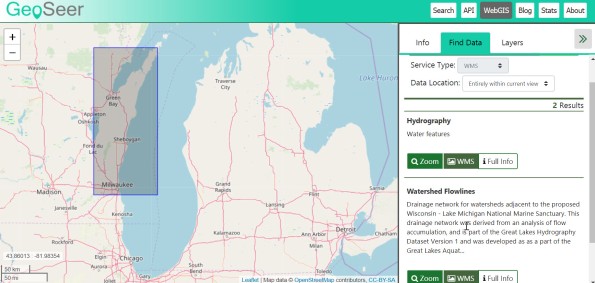
GeoSeer Mapping Interface.
With thanks to the GeoSeer team for technical assistance with this post.
–Joseph Kerski
Make scientific data FAIR – article review
In a new article in Nature, author Shelley Stall and her colleagues argue that all disciplines should follow the geosciences and demand best practice for publishing and sharing data. These authors make bold statements that I believe are long overdue, and the statements touch on many of the themes of this blog and our book, including those below. I created a video with my thoughts about this, here.
(1) Although the amount of scientific data generated are enormous, and growing each year, these data are “not being used widely enough to realize their potential” and that “most researchers come up against obstacles when they try to get their hands on data sets.” The authors show evidence that that only 1/5 of published papers typically post the supporting data in scientific repositories. While I do not have the figures at hand, this seems to be even more of an acute need in the area of research that makes use of GIS and remote sensing–how often are the links to the data sets provided? Very seldom. The authors give several key reasons why authors do not share data.
(2) The authors state that “Too much valuable, hard-won information is gathering dust on computers, disks and tapes.” I spent much of my career in federal data gathering agencies, and while much data has been digitized, not all of it has, and then — what happens when technology changes, including media (such as specific types of physical storage–see our post “Tossing the Floppies” for example) and means of access (such as the demise of most FTP sites where data was stored). On a related theme, we have documented the demise of useful geospatial data portals in these essays that may sound good in that the new and improved portals perform better, but often, data are not ported over, or are done so in a way where researchers cannot find them. Two of the many examples include the National Atlas of the USA and the Global Land Cover Facility. I have spent many hours this year alone trying to obtain data that were on both of these sites.
On a positive note, the central theme of the article is to encourage disciplines to follow the leadership of Earth Sciences and adopt the “Enabling FAIR Data Project’s Commitment Statement in the Earth, Space, and Environmental Sciences for depositing and sharing data” principles. This helps ensure that data be “findable, accessible, interoperable and reusable”. Perhaps we will see the day when the majority of articles will provide, for the reader, access to the data behind them. I do hope, however, that if authors cannot share the data for reasons of confidentiality or safety or for another valid reason, that provisions will be made for the research to still be published if it is deemed by peer review to be of value to the scientific community.

A new article in Nature discusses why data is seldom shared in published scholarly research, and what might be done about the situation.
Contributors
Gallery







Recent Comments