Archive
Exploring the Colorado Geospatial Portal
The Colorado Geospatial Portal (https://geodata.colorado.gov/) allows both trained GIS professionals and members of the general public to discover geospatial technology across the state. The site includes a spatial data portal, a map viewer to visualize various datasets, links to state and federal geospatial partners, and open resources such as trainings. The goal of the site is to provide a centralized location for all GIS users to find data, explore applications, or find contacts for their own purposes. As a longtime resident of Colorado, I can attest to the vibrancy of the GIS community here. This portal is indeed what many of us have been dreaming about for years; therefore I salute Jackie Phipps Montes, our state of Colorado GIO, and her team. Jackie says the following:
“The Spatial Data Portal aims to provide accessible and authoritative data to drive decision-making statewide. Previously, geospatial data could be found across 14 different locations such as the Colorado Information Marketplace (CIM) or individual agency websites. However, these methods either have limited geospatial functionality or rely on the end user to understand the agency structure across the state. The Spatial Data Portal tries to remove this barrier. We work with our agency partners to pull their data, maps, applications, and links to their geospatial resources. The result is one place to discover the numerous resources across the state.”
“These efforts aim to make geospatial more discoverable for a wide audience. We want our geospatial technologies, data, and resources to fully embrace the Digital Equity, Literacy, and Inclusion Initiative. The Governor’s Office of Information Technology will continue curating content for the Spatial Data Portal striving to provide relevant data, consistent sources, and to provide resources to make navigating and using geospatial technology and data easier in the State of Colorado.”



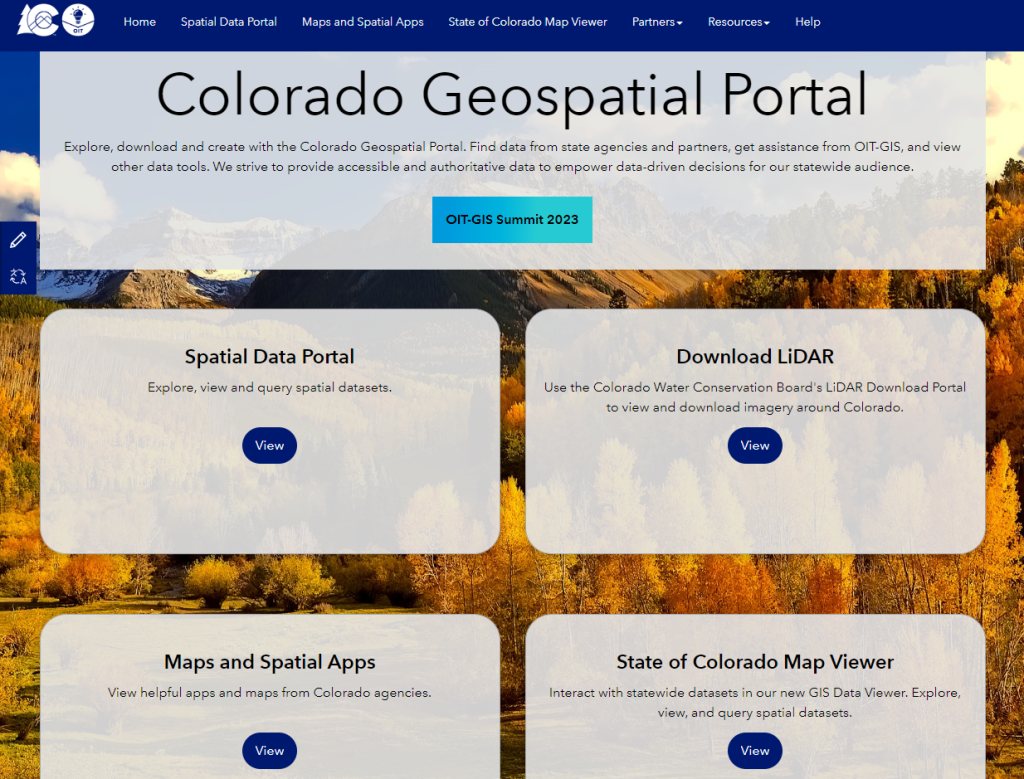
I look forward to your reactions and how you are using the portal!
—Joseph Kerski
Geospatial Commission: Best practice guide for data publishers
The UK’s Geospatial Commission and its six partner bodies, British Geological Survey, Coal Authority, HM Land Registry, Ordnance Survey, UK Hydrographic Office and Valuation Office Agency, have published a new guide with practical advice on how to optimise access to geospatial datasets across all search engines. The main recommendations highlighted in the guide are:
- Complete all the metadata fields on your data portal.
- Restrict page titles and URLs to 50-60 characters; longer titles tend to be truncated and longer URLs tend to be give a lower ranking.
- Optimise your data abstracts; write clearly, write concisely.
- Use keywords appropriately in abstract and avoid keyword lists.
- Avoid the use of special characters that may not display correctly on a webpage.
- Page longevity improves search engine ranking; try to keep your URL the same even if your data changes..
- Remove out of date or pages that are no longer maintained; these are less likely to be shown in search results that more recently updated pages.
- Avoid metadata duplication; the same information available from multiple publishers or available in more than one place makes it likely the search results will have a lower ranking than one good metadata record.
- Consider using user surveys, interviews and some of the analytic tools available, such as Google Analytics and Search Console applications, to understand what geospatial information the target audiences are looking for and finding. If necessary adjust data portal abstracts and keywords to better reflect those search parameters.
- Apply all abstract and keyword changes to all pages on your portal to ensure a consistent search ranking.
It would interesting to know if the Geospatial Commission and partners will follow up with any agencies and organisations that implement these recommendations to see how much of an improvement is possible with respect to finding and accessing online geospatial datasets.
Three Lessons for Improving Data Access
This week’s guest post is courtesy of Brian Goldin, CEO of Voyager Search.
The Needle in the Haystack
Every subculture of the GIS industry is preaching the gospel of open data initiatives. Open data promises to result in operational efficiencies and new innovation. In fact, the depth and breadth of geo-based content available rivals snowflakes in a blizzard. There are open data portals and FTP sites to deliver content from the public sector. There are proprietary solutions with fancy mapping and charting applications from the private sector. There are open source and crowd sourced offerings that grow daily in terms of volume of data and effectiveness of their solutions. There are standards for metadata. There are laws to enforce that it all be made available. Even security stalwarts in the US and global intelligence communities are making the transition. It should be easier than ever to lay your hands on the content you need. But now, we struggle to find the needle in a zillion proverbial haystacks.
Ironically, GIS users and data consumers need to be explorers and researchers to find what they need. We remain fractured about how to reach the nirvana where not only is the data open, but also it is accurate, well documented, and available in any form. We can do better, and perhaps we learn some lessons from consumer applications that changed the way we find songs, buy a book, or discover any piece of information on the web.
Lesson one: Spotify for data.
In 1999, Napster landed a punch, knocking the wind out of the mighty music publishing industry. When the dust settled, the music industry prevailed, but it did so in a weakened state with their market fundamentally changed. Consumers’ appetite for listening to whatever they wanted for free made going back to business as usual impossible. Spotify ultimately translated that demand into an all-you-can-eat music model. The result is that in 2014 The New Yorker reported that Spotify’s user base was more than 50 million worldwide with 12.5 million subscribers. By June 2015, it was reportedly 20 million subscribers. Instead of gutting the music publishers, Spotify helped them to rebound.
Commercial geospatial and satellite data providers should take heed. Content may well be king, but expensive, complicated pricing models are targets for disruption. It is not sustainable to charge a handful of customer exorbitant fees for content or parking vast libraries of historical data on the sidelines while smaller players like Skybox, gather more than 1 terabyte of data a day and open source projects gather road maps of the world. Ultimately, we need a business model that gives users an all-you-can-eat price that is reasonable rather than a complex model based on how much the publisher thinks you can pay.
Lesson two: Google for GIS.
We have many options for finding the data, which means that we have a zillion stovepipes to search. What we need is unification across those stovepipes so that we can compare and contrast their resources to find the best content available.
This does not mean that we need one solution for storing the data and content. It just means we need one place for searching and finding all of the content no matter where it exists, what it is, what software created it or how it is stored. Google does not house every bit of data in a proprietary solution, nor does it insist on a specific standard of complex metadata in order for a page to be found. It if did, Internet search would resemble the balkanised GIS search experience we have today. But when I want GIS content, I have to look through many different potential sources to discover what might be the right one.
What is required is the ability to crawl all of the data, content, services and return a search page that shows the content on a readable, well formatted page with some normalised presentation of metadata that includes the location, the author, a brief description and perhaps the date it was created, no matter where it this resides. We need to enable people to compare content with a quick scan and then dig deeper into whatever repository houses it. We need to use their search results to inform the next round of relevancy and even to anticipate the answers to their questions. We need to enable sharing and commenting and rating on those pages to show where and how user’s feel about that content. This path is well-worn in the consumer space, but for the GIS industry these developments lag years behind as limited initiatives sputter and burn out.
Lesson 3. Amazon for geospatial.
I can find anything I want to buy on Amazon, but it doesn’t all come from an Amazon warehouse nor does Amazon manufacture it. All of the content doesn’t need to be in one place, one solution or one format; so long as it is discoverable in and deliverable from one place. Magically, anything I buy can be delivered through a handy one-click delivery mechanism! Sure, sometimes it costs money to deliver it, other times it’s free, but consumers aren’t challenged to learn a new checkout system each and every time they buy from a new vendor. They don’t have to call a help desk for assistance with delivery.
Today, getting your hands on content frequently requires a visit an overburdened GIS government staffer who will deliver the content to you. Since you might not be able to see exactly what they have, you almost always ask for more than you need. You’ll have no way of knowing when or how that data was updated. What should be as easy as clip-zip-and-ship delivery — the equivalent of gift-wrapping a package on Amazon — seems a distant dream. But why is this?
While agency leadership extols the virtues of open government initiatives, if their content is essentially inaccessible, the risk of being punished for causing frustration is minimal compared with that of exposing bad data or classified tidbits. So why bother when your agency’s first mandate is to accomplish some other goal entirely and your budget is limited? Government’s heart is certainly behind this initiative, but is easily outweighed by legitimate short-term risks and the real world constraints on human and financial resources.
The work of making public content discoverable in an open data site as bullet proof as Amazon’s limitless store seems can and should be done by industry with the support of the government so that everyone may benefit. In the private sector, we will find a business model to support this important work. But here’s the catch. This task will never be perceived as being truly open if it is done by a company that builds GIS software. The dream of making all GIS content discoverable and open, requires that it everyone’s products are equally discoverable. That’s a huge marketing challenge all by itself. Consider that Amazon’s vision of being the world’s largest store does not include making all of the stuff sold there. There really is a place for a company to play this neutral role between the vendors, the creators of the content and the public that needs it.
On the horizon
We have come so far in terms of making content open and available. The data are out there in a fractured world. What’s needed now isn’t another proprietary system or another set of standards from an open source committee. What’s really needed is a network of networks that makes single search across all of this content, data and services possible whether it’s free or for a fee. We should stop concerning ourselves with standards for this or that, and let the market drive us toward those inevitable best practices that help our content to be found. I have no doubt that the brilliant and creative minds in this space will conquer this challenge.
Brian Goldin, CEO of Voyager Search.
2015 and Beyond: Who will control the data?
Earlier this year Michael F. Goodchild, Emeritus Professor of Geography at the University of California at Santa Barbara, shared some thoughts about current and future GIS-related developments in an article for ArcWatch. It was interesting to note the importance attached to the issues of privacy and the volume of personal information that is now routinely captured through our browsing habits and online activities.
Prof. Goodchild sees the privacy issue as essentially one of control; what control do we as individuals have over the data that are captured about us and how that data are used. For some the solution may be to create their own personal data stores and retreat from public forums on the Internet. For others, an increasing appreciation of the value of personal information to governments and corporations, may offer a way to reclaim some control over their data. The data could be sold or traded for access to services, a trend we also commented on in a previous post.
Turning next to big data, the associated issues were characterised as the three Vs:
- Volume—Capture, management and analysis of unprecedented volumes of data
- Variety—Multiple data sources to locate, access, search and retrieve data from
- Velocity—Real-time or near real-time monitoring and data collection
Together the three Vs bring a new set of challenges for data analysts and new tools and techniques will be required to process and analyse the data. These tools will be required to not only better illustrate the patterns of current behaviour but to predict more accurately future events, such as extreme weather and the outbreak and the spread of infectious diseases, and socio-economic trends. In a recent post on GIS Lounge Zachary Romano described one such initiative from Orbital Insights, a ‘geospatial big data’ company based in California. The company is developing deep learning processes that will recognise patterns of human behaviour in satellite imagery and cited the examples of the number of cars in a car park as an indicator of retail sales or the presence of shadows as an indicator of construction activity. As the author noted, ‘Applications of this analytical tool are theoretically endless‘.
Will these new tools use satellite imagery to track changes at the level of individual properties? Assuming potentially yes, the issue of control over personal data comes to the fore again, only this time most of us won’t know what satellites are watching us, which organisations or governments control those satellites and who is doing what with our data.
Public Domain Data and the Data Manifesto
Last year the UK’s Royal Statistical Society released their Data Manifesto, highlighting ‘….the potential of data to improve policy and business practice’, and stressing the importance of what the Society referred to as data literacy. A central theme in the manifesto is the role of public domain data, both the quality of the information that is available and the trust placed in it by the individuals and organisations who use that data. Although much has been accomplished over recent years with respect to providing better access to government data, the Society specifically mention the value in continuing to open up addressing and geospatial data as ‘..core reference data upon which society depends and also act as a catalyst to release economic value from other open datasets’.

Royal Statistical Society Data Manifesto
Just as important as having access to data sources are the skills required to analyse and interpret that data; the data literacy skills that will be the foundation of the new data economy – basic data handling, quantitative skills and the ability to interpret data using the best technologies for the task.
As data users in this new data economy we also need the critical skills described by Joseph Kerski in his post on being critical of data; yes we need access to the public domain and open data, yes we need to be able to find data and yes we need the skills to work with the data, but we also need to be able to determine the quality of the data and how appropriate the data are for our individual requirements.
Contributors
Gallery







Recent Comments